
Linear Prediction Analysis of Speech
Source-system modeling of speech signals using LP analysis
The vocal tract system can be modeled as a time-varying all-pole filter using segmental analysis. The segmental analysis corresponds to the processing of speech as short (10-30 ms) overlapped (5-15 ms) windows. The vocal tract system is assumed to be stationary within the window and is modeled as an all-pole filter of order using linear prediction (LP) analysis. The LP analysis works on the principle that a sample value in a correlated, stationary sequence can be predicted as a linear weighted sum of the past few () samples. If denotes a sequence of speech samples, then the predicted value at the time instant is given by
where is the set of linear predictor coefficients (LPC) and is the order of the LP filter. The error at time and the sum of squared errors are given by
The cost function is minimized with respect to over the interval (autocorrelation formulation) as,
This minimization leads to a set of normal equations,
where
is the autocorrelation sequence. The solution of these normal equations gives the values of the predictor coefficients . The error signal obtained by inverse filtering the speech signal is referred to as the LP residual. The smooth variations (highly correlated) in the speech signal are captured by the LPCs and are attributed to the vocal tract characteristics. The complex poles of the LP filter occur as conjugate pairs, and each pair represents a resonator cavity, with a maximum response at a frequency (called as resonant frequency) where the poles are located on the z-plane. The vocal tract can be considered as a cascade of resonator cavities with different shapes and sizes. The resonant frequencies of these cavities are referred to as formants. The LP residual signal has large error values at regular intervals and can be attributed to the periodic impulses of excitation. Hence the LP residual is a good approximation to the excitation source signal and can be used further to extract the excitation source characteristics. A segment of voiced speech (windowed), frequency response of the inverse filter and the corresponding LP residual are shown in Figure 1.
The vocal tract system can be modeled as a time-varying all-pole filter using segmental analysis. The segmental analysis corresponds to the processing of speech as short (10-30 ms) overlapped (5-15 ms) windows. The vocal tract system is assumed to be stationary within the window and is modeled as an all-pole filter of order using linear prediction (LP) analysis. The LP analysis works on the principle that a sample value in a correlated, stationary sequence can be predicted as a linear weighted sum of the past few () samples. If denotes a sequence of speech samples, then the predicted value at the time instant is given by
where is the set of linear predictor coefficients (LPC) and is the order of the LP filter. The error at time and the sum of squared errors are given by
The cost function is minimized with respect to over the interval (autocorrelation formulation) as,
This minimization leads to a set of normal equations,
where
is the autocorrelation sequence. The solution of these normal equations gives the values of the predictor coefficients . The error signal obtained by inverse filtering the speech signal is referred to as the LP residual. The smooth variations (highly correlated) in the speech signal are captured by the LPCs and are attributed to the vocal tract characteristics. The complex poles of the LP filter occur as conjugate pairs, and each pair represents a resonator cavity, with a maximum response at a frequency (called as resonant frequency) where the poles are located on the z-plane. The vocal tract can be considered as a cascade of resonator cavities with different shapes and sizes. The resonant frequencies of these cavities are referred to as formants. The LP residual signal has large error values at regular intervals and can be attributed to the periodic impulses of excitation. Hence the LP residual is a good approximation to the excitation source signal and can be used further to extract the excitation source characteristics. A segment of voiced speech (windowed), frequency response of the inverse filter and the corresponding LP residual are shown in Figure 1.
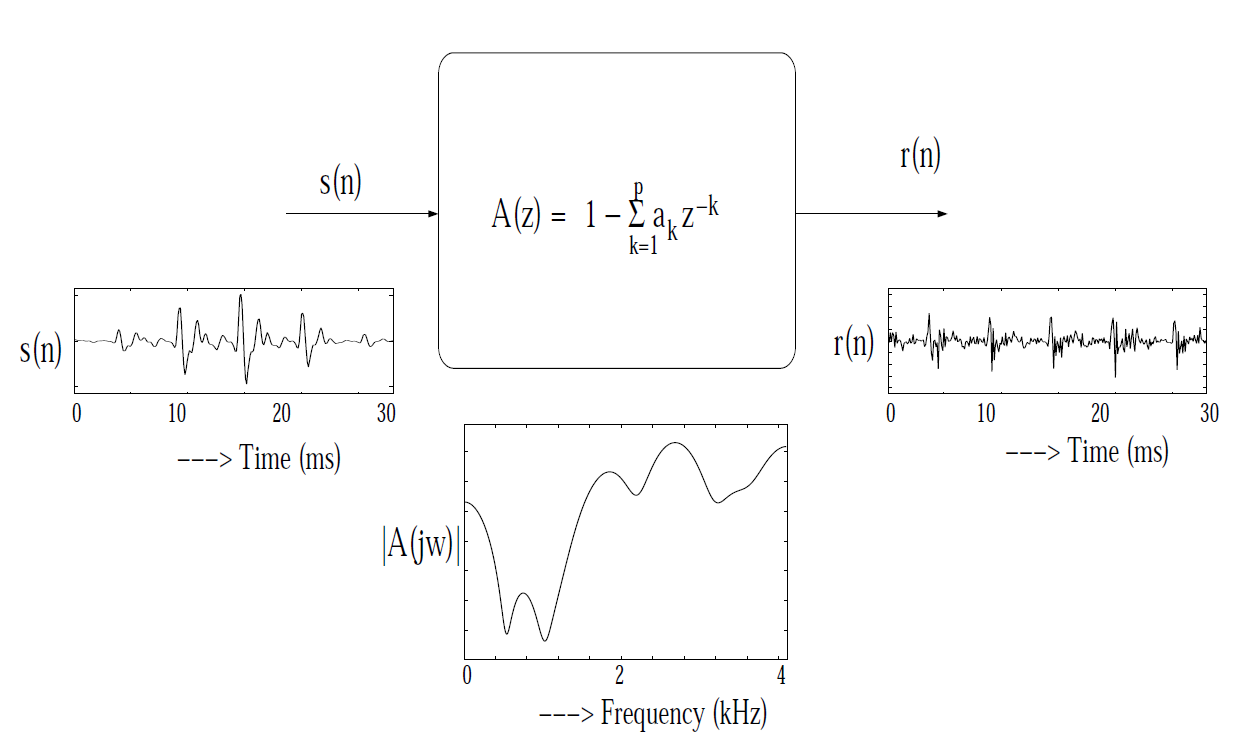
Inverse filtering the speech signal
for estimating the excitation source (LP residual) signal.
Short time spectrum, LP spectrum and Inverse spectrum
The short-time spectrum consists of a range of frequencies (magnitude and phase components) present in a small segment (10-30 ms) of a signal. The inverse spectrum is an all-zero model derived from . The LP spectrum is an all-pole model given by:
The LP spectrum can approximate the envelope of the short-time spectrum depending on the choice of LP order. The gross envelope is captured at low LP orders such as 1 or 3. The short-time spectral envelope is finely matched as the LP order increases. One of the main issues in LP analysis is the choice of appropriate LP order. Figures 2 and 3 show the short-time spectrum, LP spectrum, and the inverse LP spectrum for a segment of voiced (/a/) and unvoiced speech (/s/) respectively.
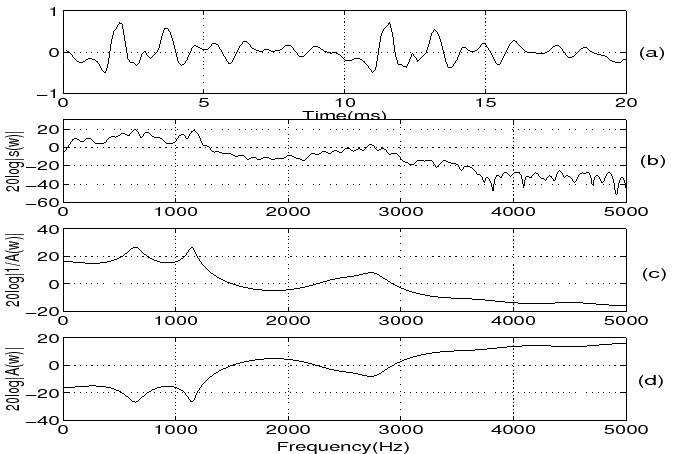
Figure 2:
(a) Segment of voiced speech /a/
(b) Short time spectrum
(c) LP spectrum
(d) Inverse spectrum (LP order: 10)
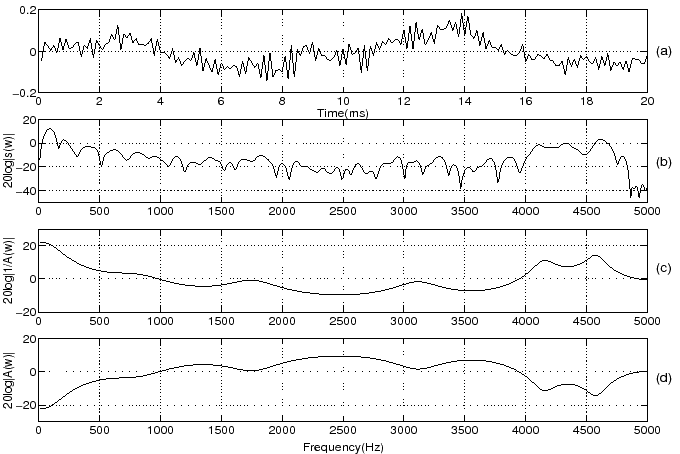
Figure 3:
(a) Segment of unvoiced speech /s/
(b) Short time spectrum
(c) LP spectrum
(d) Inverse spectrum (LP order: 10)
LP residual for voiced and unvoiced segments
LP residual signal is obtained by passing the speech signal through inverse filter designed with LP coefficients (LPCs). The block diagram of the inverse filter is shown in Figure 4.

Voiced and unvoiced speech segments and their LP residual signals are shown in Figure 5.
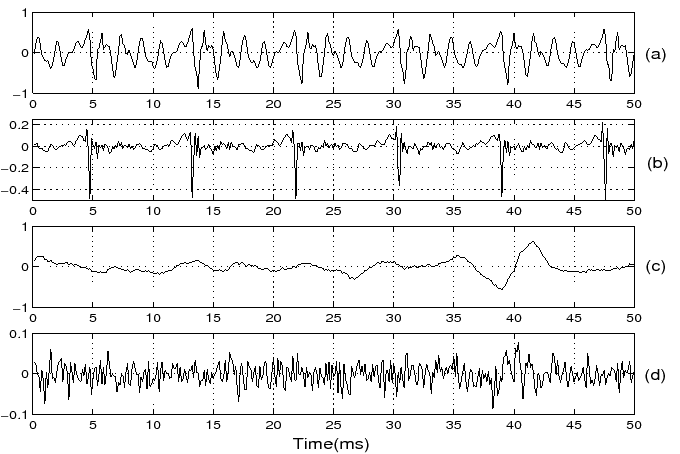
(a) Segment of voiced speech /a/ and its
(b) LP residual signal,
(c) segment of unvoiced speech /s/ and its
(d) LP residual signal (LP order: 10).
Autocorrelation function for voiced/unvoiced speech segments and their LP residuals
- Autocorrelation function of the signal (x[n]) is computed as
- The autocorrelation function for the voiced speech segment and its LP residual signal is shown in Figure 6.
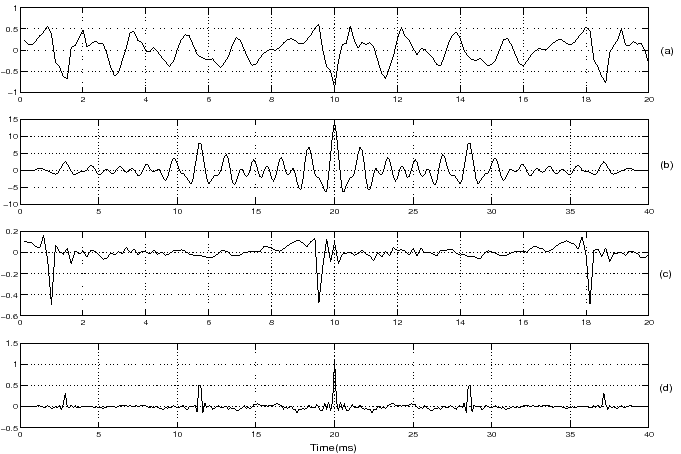
Figure 6:
(a) Segment of voiced speech /a/ and its
(b) autocorrelation function,
(c) LP residual for the voiced speech segment and its
(d) autocorrelation function (LP order: 10).
The autocorrelation function for the unvoiced speech segment and its LP residual signal is shown in Figure 7.
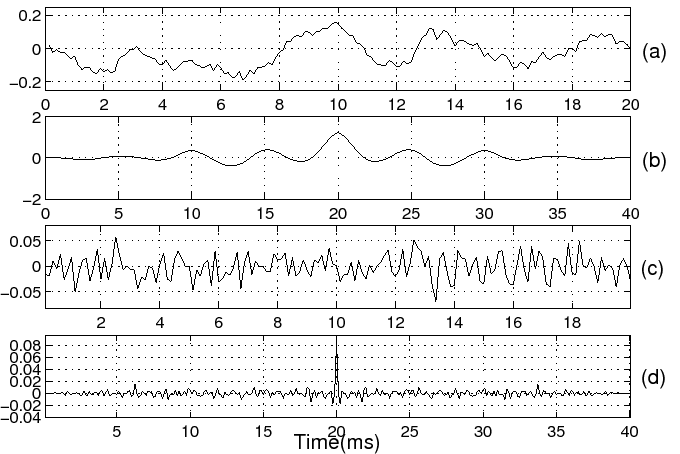
(a) Segment of unvoiced speech /s/
(b) Autocorrelation function
(c) LP residual for the unvoiced speech segment
(d) Autocorrelation function (LP order: 10)
Glottal pulse shape in voiced portion of a speech signal
- By integrating the LP residual we can obtain the glottal pulse shape, it is also known as glottal volume velocity.
- A segment of voiced speech its LP residual and glottal pulse (glottal volume velocity) waveforms are shown in Figure 8.
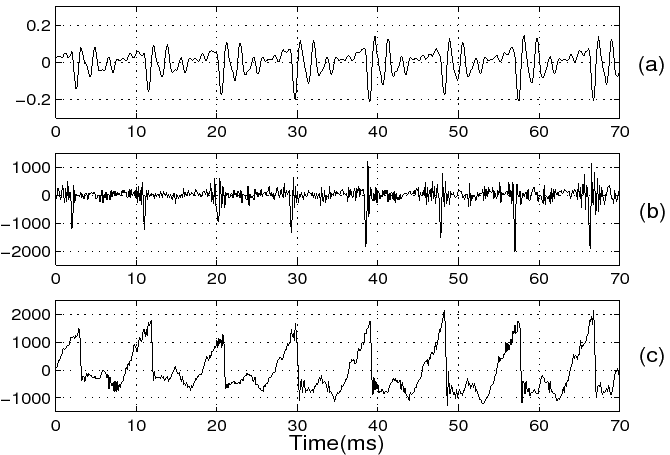
Figure 8:
(a) Segment of voiced speech /a/
(b) LP residual
(c) Glottal pulse waveform (LP order: 10)
LP spectrum for different LP orders
- Compute LPCs for different LP orders (14, 10, 6, 3 and 1), and compute LP spectrum for each set of LPCs.
- A segment of voiced speech and its LP spectrum for different LP orders (14, 10, 6, 3 and 1) are shown in Figure 9.
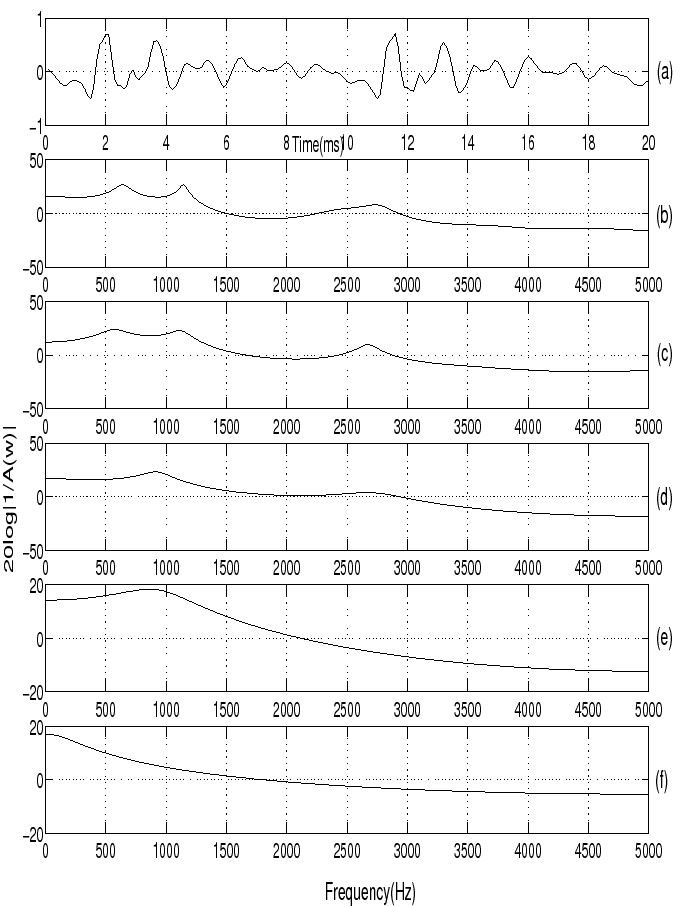
Figure 9:
(a) Segment of voiced speech /a/
(b) LP spectrum for LP order 14
(c) LP spectrum for LP order 10
(d) LP spectrum for LP order 6
(e) LP spectrum for LP order 3
(f) LP spectrum for LP order 1
Normalized error for different LP orders for voiced/unvoiced speech segments
- Normalized error is obtained by normalizing the LP residual energy with respect to speech signal energy.
where
denote the residual and signal energies, respectively.
- Normalized error plots for voiced and unvoiced segments of speech for different LP orders are shown in Figure 10.
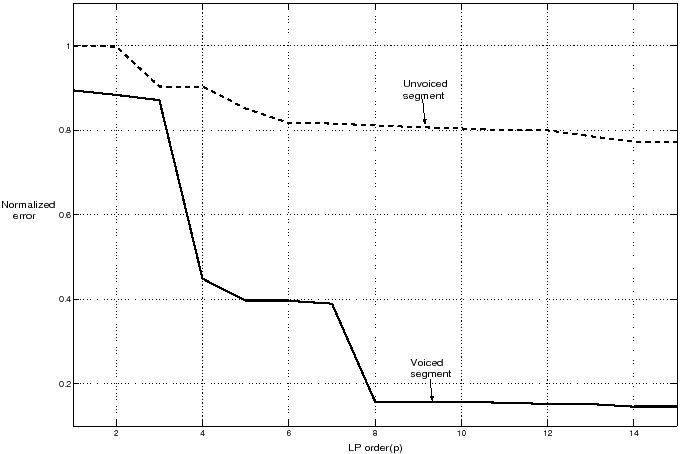
Figure 10:
Normalized error for voiced and unvoiced speech segments
for different LP orders.